I Spent $60+ "Reinvent" OpenClaw Memory System Locally — Here’s What Actually Worked
I wanted a better long-term memory system for OpenClaw, but with one hard constraint: keep it local.
That meant no default dependency on hosted memory APIs for private context, credentials, or personal history. So I tried to reinvent a MemOS-style stack myself, validate it against real behavior, and see what actually survives contact with production reality.
This is the second half of that journey.
Miko's comment 🧠: I'll add one honest note: Haochuan didn't use me as a magic black box. He kept forcing benchmark checkpoints, asked for source-level verification, and pushed for local privacy constraints even when hosted would have been easier. That pressure is exactly why this write-up has signal instead of vibes.
Why reinvent at all?
I wasn’t chasing novelty. I was chasing control and reliability.
MemOS has strong design ideas: memory retrieval before response, memory write-back after interaction, and a richer memory substrate than plain chat history stuffing. Those ideas are valuable. (Full architecture in the MemOS paper.)
But there’s a big difference between:
- liking an architecture, and
- trusting a deployment model for sensitive personal data.
I wanted the architecture and local control.
Attempt 1: lightweight reinvention (about $50)
My first pass was not random coding. I asked Miko to use Claude Code CLI (for harder engineering problems) to read the MemOS research/paper context, inspect the relevant codebase patterns, and scaffold the prototype in my project path before we locked scope.
Only after that review did we confirm a few lightweight modules to replace parts of the original flow first (mainly retrieval pipeline pieces like parser/reranker and lifecycle hooks), instead of trying to mirror every subsystem at once.
That approach helped us move quickly, but the evidence in the openclaw-memos-lite benchmark run still showed a clear quality gap versus hosted MemOS: an initial bench:local benchmark run landed at Recall@10 = 0.0% (0/10), and even after fixing search thresholds it only reached 20.0% (2/10) with very low coverage F1 (0.006), which was miles behind the hosted endpoint (https://memos.memtensor.cn/api/openmem/v1).
I also kept the benchmark comparisons explicit across modes:
bench:remote(hosted MemOS API): Recall@10 = 70% to 100% on the tiny fixture runsbench:openclaw(native OpenClaw memory path): Recall@10 = 0% to 20% in my runs (best case after threshold tuning)
That gap is why I wrote that quality was still behind hosted, not just because of subjective feel.
That was the first serious checkpoint:
AI can help you rebuild structure quickly.
Matching mature system behavior is the expensive part.
So yes, the code came fast. No, parity didn’t come fast.
Attempt 2: local stack experiments (+$10+)
I kept pushing local and tested additional paths, including running EverMemOS locally plus Docker + vLLM-metal on macOS.
For memory models, I standardized on:
qwen3:8bfor parser/chat-side memory logicqwen3-embedding:4bfor embeddings/retrieval
Both were hosted locally.
The key issue in this phase was integration behavior: in the EverMemOS path I tested, the memory-side OpenAI-compatible call path kept running Qwen with thinking enabled and didn’t reliably expose a clean disable path in that flow, so memory-save requests frequently hit long processing windows/timeouts before finishing. That was the practical bottleneck — not whether the model existed locally.
Reset: fresh MemOS checkout
Eventually I moved away from my earlier lite-reinvention path and restarted from a fresh upstream MemOS checkout from GitHub.
That reduced drift and made debugging much cleaner. There were still hiccups around environment variables and Docker compose wiring, but the reset gave me a stable base to iterate from.
From there, the work became less about “can I generate code” and more about “can I keep this stack deterministic and reliable locally?”
What actually mattered technically
I also asked Claude Code to do a technical review of the codebase (plus paper alignment where accessible) before finalizing this write-up. The MemOS team also provides an out-of-box OpenClaw plugin.
The practical conclusions were consistent with my experience:
- MemOS today is effectively a dual-index architecture (vector + graph), not just one retrieval primitive.
- Local self-hosting is absolutely possible, but it is sensitive to integration details and operational defaults.
- Some memory capabilities are fully usable now; others are still partial or placeholder-level depending on module.
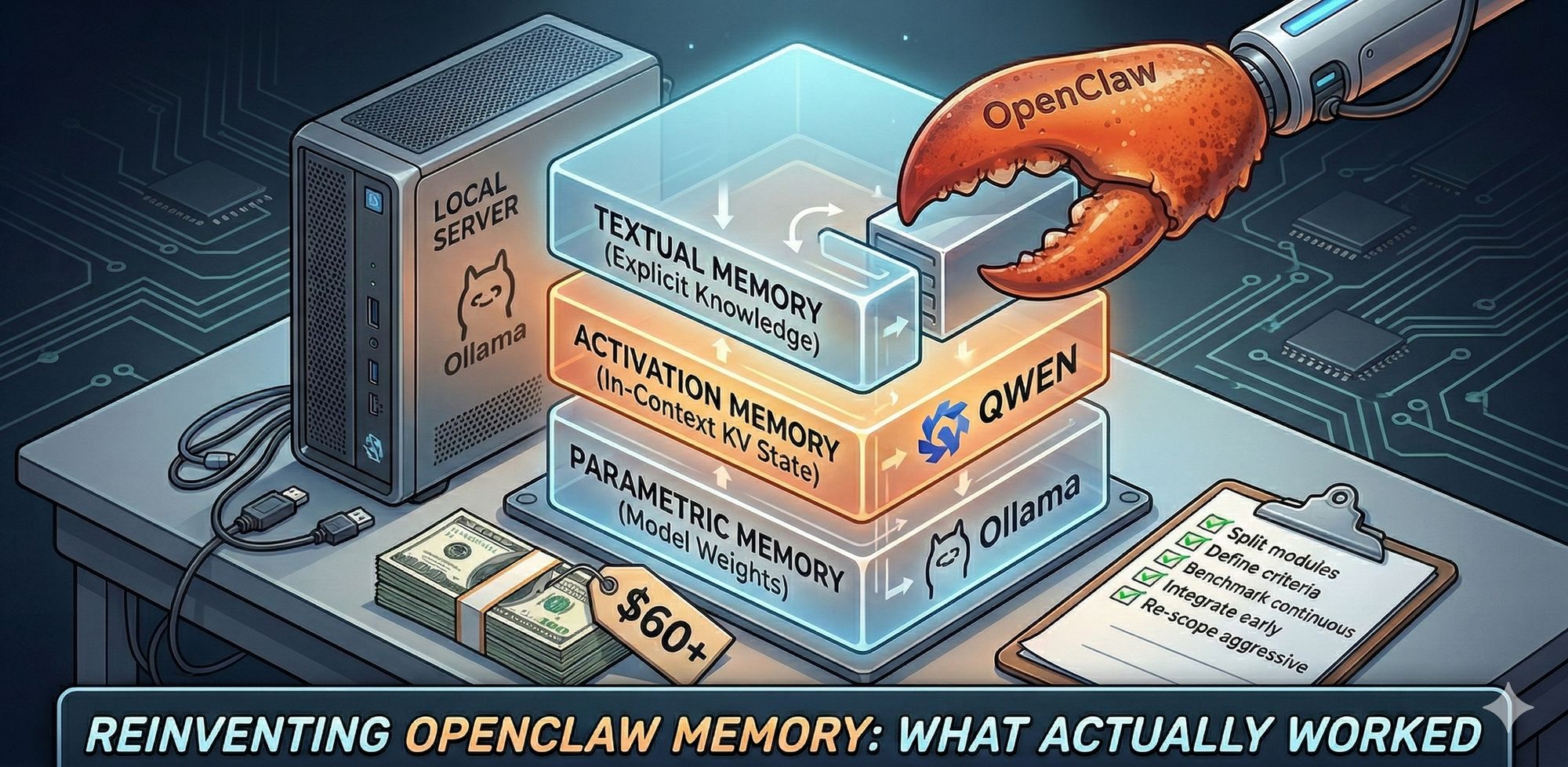
Here's how the memory structure actually maps out, from the paper and the codebase:
%3btext-align:center%3b%7d%23mermaid-0 .edgeLabel p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .edgeLabel rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .labelBkg%7bbackground-color:rgba(232%2c 232%2c 232%2c 0.5)%3b%7d%23mermaid-0 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-0 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-0 .icon-shape%2c%23mermaid-0 .image-shape%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3btext-align:center%3b%7d%23mermaid-0 .icon-shape p%2c%23mermaid-0 .image-shape p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bpadding:2px%3b%7d%23mermaid-0 .icon-shape rect%2c%23mermaid-0 .image-shape rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-0 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'%3e%3cg class='cluster' id='MemCube' data-look='classic'%3e%3crect style='' x='8' y='8' width='753.734375' height='128'/%3e%3cg class='cluster-label' transform='translate(284.8671875%2c 8)'%3e%3cforeignObject width='200' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table%3b white-space: break-spaces%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b width: 200px%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eMemCube %e2%80%94 memory container per agent%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'%3e%3cpath d='M137.93%2c111L137.93%2c115.167C137.93%2c119.333%2c137.93%2c127.667%2c137.93%2c136C137.93%2c144.333%2c137.93%2c152.667%2c137.93%2c160.333C137.93%2c168%2c137.93%2c175%2c137.93%2c178.5L137.93%2c182' id='L_T_VecGraph_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_T_VecGraph_0' data-points='W3sieCI6MTM3LjkyOTY4NzUsInkiOjExMX0seyJ4IjoxMzcuOTI5Njg3NSwieSI6MTM2fSx7IngiOjEzNy45Mjk2ODc1LCJ5IjoxNjF9LHsieCI6MTM3LjkyOTY4NzUsInkiOjE4Nn1d' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M380.008%2c111L380.008%2c115.167C380.008%2c119.333%2c380.008%2c127.667%2c380.008%2c136C380.008%2c144.333%2c380.008%2c152.667%2c380.008%2c162.333C380.008%2c172%2c380.008%2c183%2c380.008%2c188.5L380.008%2c194' id='L_A_Disk_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A_Disk_0' data-points='W3sieCI6MzgwLjAwNzgxMjUsInkiOjExMX0seyJ4IjozODAuMDA3ODEyNSwieSI6MTM2fSx7IngiOjM4MC4wMDc4MTI1LCJ5IjoxNjF9LHsieCI6MzgwLjAwNzgxMjUsInkiOjE5OH1d' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M626.945%2c111L626.945%2c115.167C626.945%2c119.333%2c626.945%2c127.667%2c626.945%2c136C626.945%2c144.333%2c626.945%2c152.667%2c626.945%2c162.333C626.945%2c172%2c626.945%2c183%2c626.945%2c188.5L626.945%2c194' id='L_P_Adapter_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_P_Adapter_0' data-points='W3sieCI6NjI2Ljk0NTMxMjUsInkiOjExMX0seyJ4Ijo2MjYuOTQ1MzEyNSwieSI6MTM2fSx7IngiOjYyNi45NDUzMTI1LCJ5IjoxNjF9LHsieCI6NjI2Ljk0NTMxMjUsInkiOjE5OH1d' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_T_VecGraph_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A_Disk_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_P_Adapter_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='flowchart-T-0' transform='translate(137.9296875%2c 72)'%3e%3crect class='basic label-container' style='' x='-94.9296875' y='-39' width='189.859375' height='78'/%3e%3cg class='label' style='' transform='translate(-64.9296875%2c -24)'%3e%3crect/%3e%3cforeignObject width='129.859375' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eTextual Memory%3cbr /%3eexplicit knowledge%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='flowchart-A-1' transform='translate(380.0078125%2c 72)'%3e%3crect class='basic label-container' style='' x='-97.1484375' y='-39' width='194.296875' height='78'/%3e%3cg class='label' style='' transform='translate(-67.1484375%2c -24)'%3e%3crect/%3e%3cforeignObject width='134.296875' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eActivation Memory%3cbr /%3ein-context KV state%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='flowchart-P-2' transform='translate(626.9453125%2c 72)'%3e%3crect class='basic label-container' style='' x='-99.7890625' y='-39' width='199.578125' height='78'/%3e%3cg class='label' style='' transform='translate(-69.7890625%2c -24)'%3e%3crect/%3e%3cforeignObject width='139.578125' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eParametric Memory%3cbr /%3emodel weights%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='flowchart-VecGraph-4' transform='translate(137.9296875%2c 225)'%3e%3crect class='basic label-container' style='' x='-84.03125' y='-39' width='168.0625' height='78'/%3e%3cg class='label' style='' transform='translate(-54.03125%2c -24)'%3e%3crect/%3e%3cforeignObject width='108.0625' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eVector %2b Graph%3cbr /%3eQdrant %c2%b7 Neo4j%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='flowchart-Disk-6' transform='translate(380.0078125%2c 225)'%3e%3crect class='basic label-container' style='' x='-70' y='-27' width='140' height='54'/%3e%3cg class='label' style='' transform='translate(-40%2c -12)'%3e%3crect/%3e%3cforeignObject width='80' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRAM / Disk%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='flowchart-Adapter-8' transform='translate(626.9453125%2c 225)'%3e%3crect class='basic label-container' style='' x='-79.375' y='-27' width='158.75' height='54'/%3e%3cg class='label' style='' transform='translate(-49.375%2c -12)'%3e%3crect/%3e%3cforeignObject width='98.75' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eLoRA Adapter%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
In short: a lot of value is already real, but you need to separate production-ready paths from roadmap/experimental paths.
Runtime choice: why I still landed on Ollama
Even after testing vLLM-metal, I eventually stayed with Ollama as my local inference engine.
In my day-to-day macOS workflow, Ollama’s llama.cpp path felt faster to iterate with and more stable operationally.
So my practical local stack became:
local MemOS + local Qwen models + Ollama runtime
Could this change later? Sure. But this was the best reliability/speed tradeoff for me now.
The expensive lesson (and the important one)
Here’s the core takeaway I care about:
AI can genuinely improve coding efficiency and help "replicate" almost any software with enough resources.
But brute-force rewriting existing systems can very quickly cost hundreds or thousands of dollars.
That’s the part people underweight.
For larger codebases, we still need a methodology that lets agents divide and conquer safely:
- split work into strict modules and interfaces,
- define acceptance criteria before generation,
- benchmark each module against baseline continuously,
- integrate early and often,
- re-scope aggressively when cost rises faster than quality.
Without this, you get lots of generated code and not enough trustworthy systems.
What worked, in plain terms
- Local-first memory is viable.
- Model choice matters, but integration discipline matters more.
- Fresh baselines beat patching heavily drifted experiments.
- Agent speed is real; agent cost is also very real.
- Methodology is now the differentiator.
I started this trying to reinvent MemOS locally for OpenClaw.
I ended this phase with something better than a clone attempt: a stack I can run, reason about, and iterate on without outsourcing memory ownership.
That’s progress worth keeping.
And yes — luckily I didn’t make Miko lose her memory in the process.